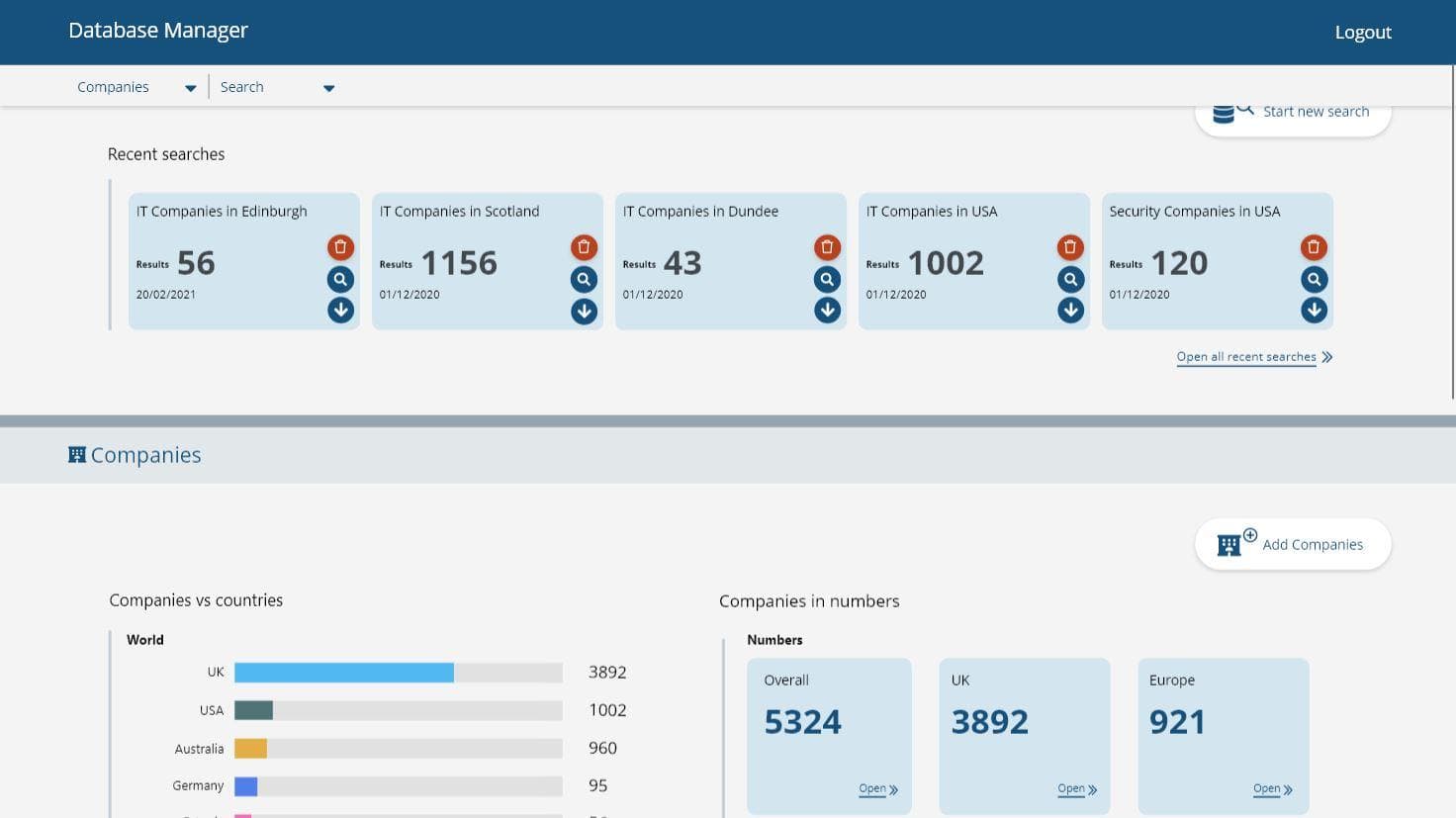
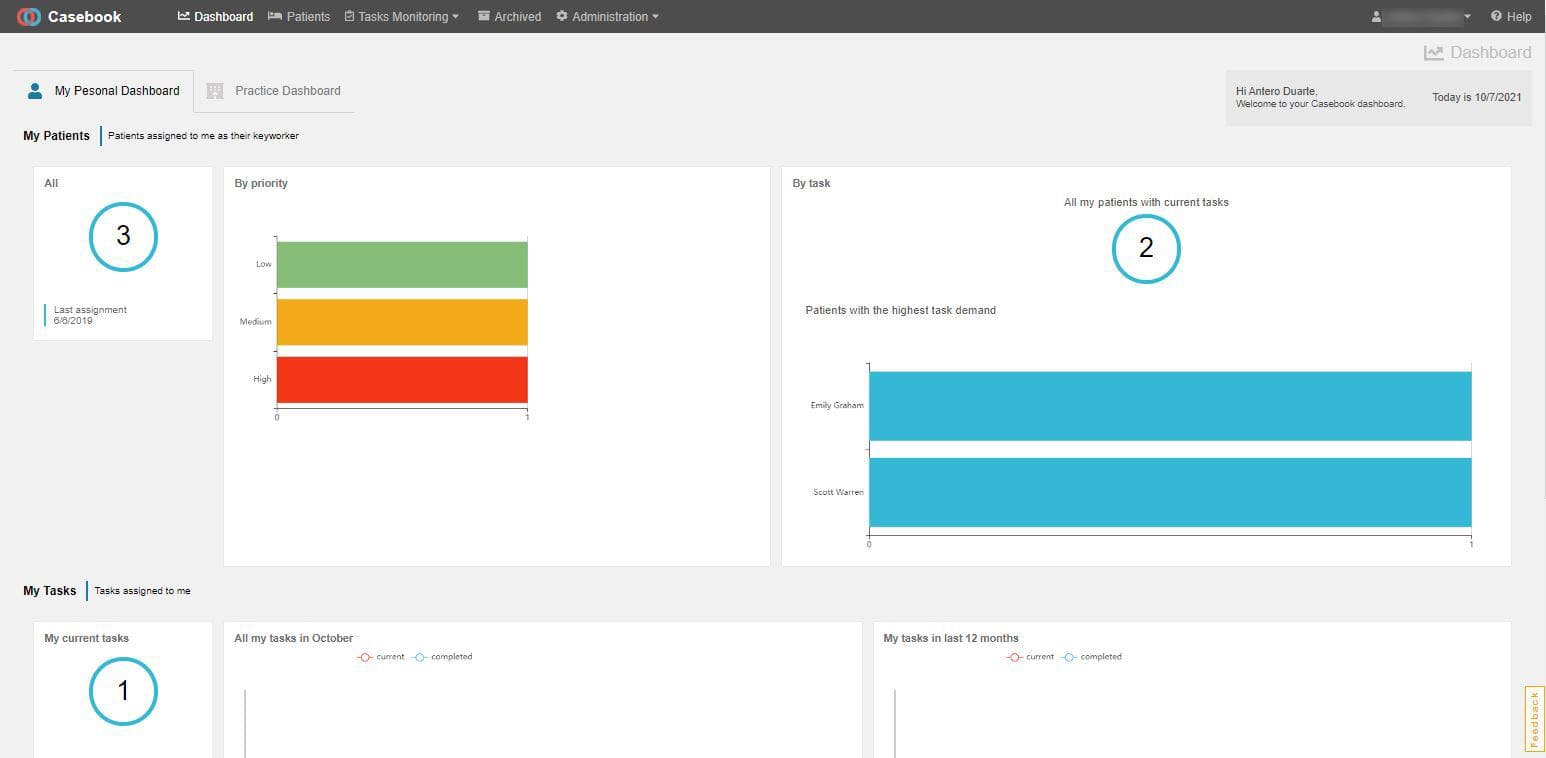
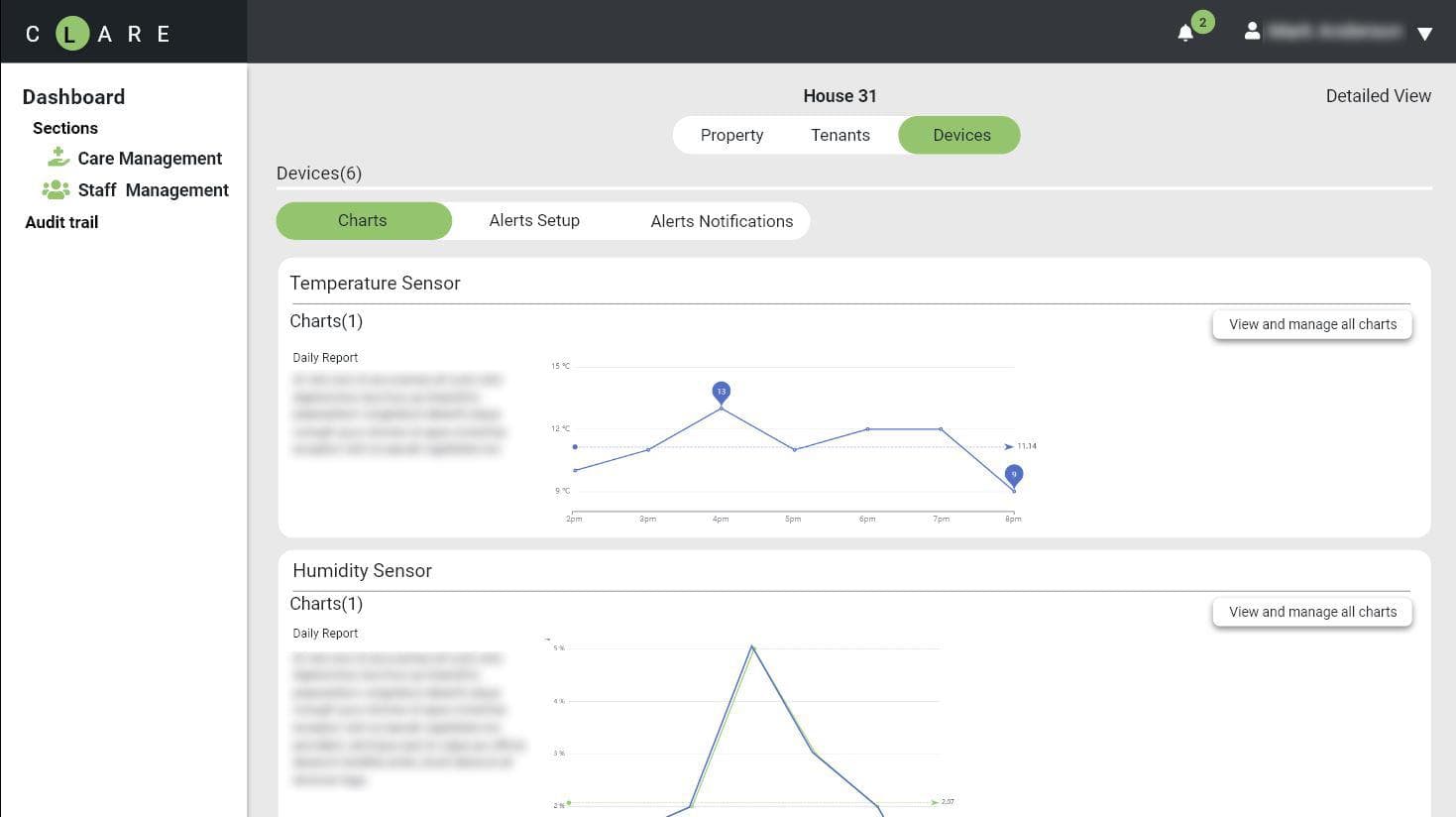
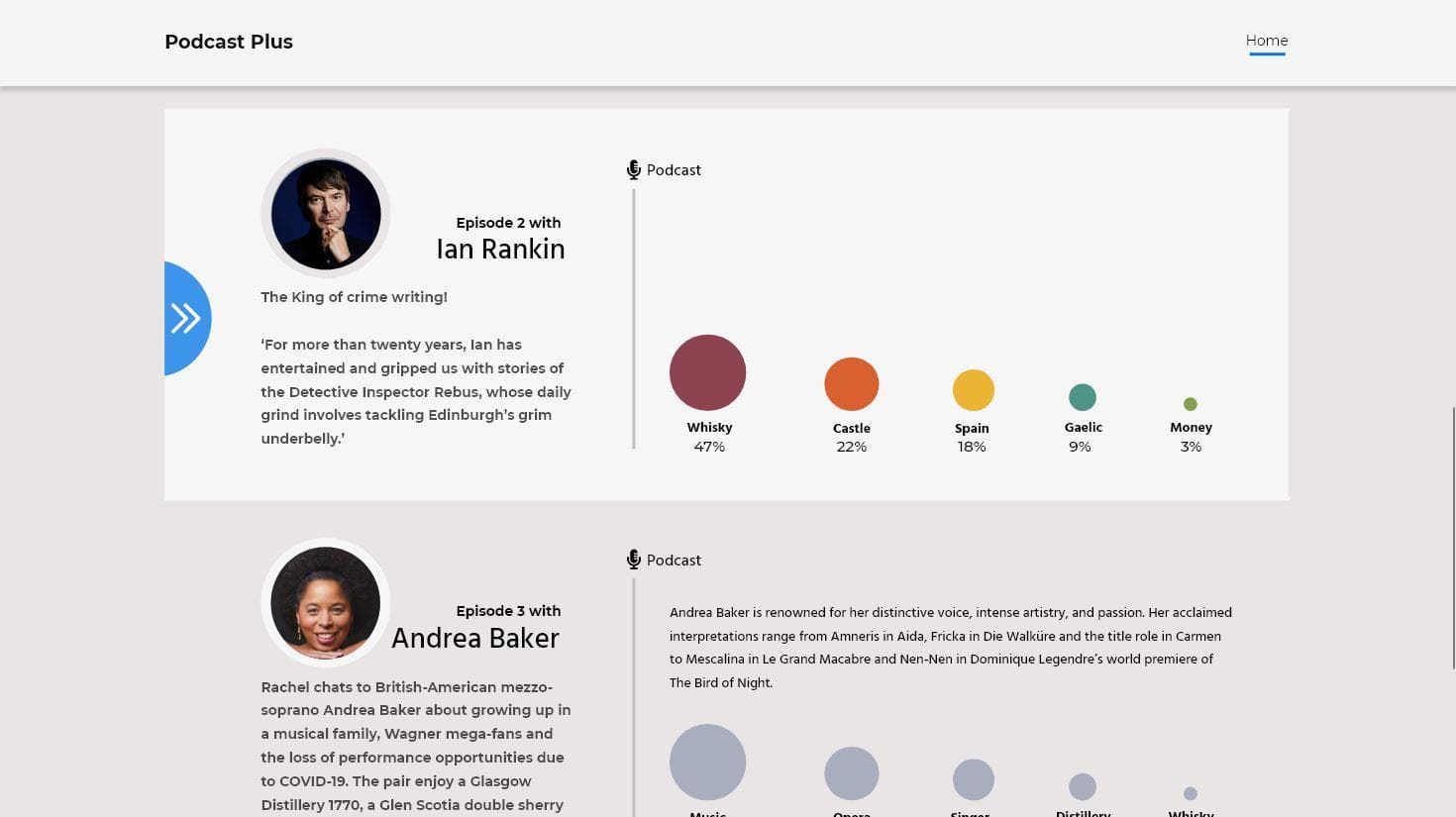
We use data, analysis, and technology to help organisations prosper and grow
Our experience has assisted many organisations to improve their capacity to use data to gain greater insights and value. We work with both public and private sector clients.
Wallscope has a range of interests, currently we are working on how the Sustainable Development Goals can be best used by organisations to benchmark their goals, policies and assets to optimise investment decisions and operational processes. This allows organisations to use sustainability impact metrics to assist analysis and reporting against the range of themes associated with sustainable growth.
With that we assessed the application of our graph-based technologies to create bespoke linked data applications which can use a wide range of data sources to best understand operational impact and sustainability performance within a structured Resource Description Framework.
Or, browse our site to learn more about our work with Data, Analysis and Technology using semantic technologies, RDF, Knowledge Graphs for creating linked data applications that support enterprise solutions which improve data sharing and consumption.